目录
在当今大模型技术飞速发展的浪潮中,混合专家模型(Mixture-of-Experts, MoE)以其独特的稀疏激活特性,有效解决了模型规模与计算效率之间的平衡难题,已成为构建千亿乃至万亿参数大模型的核心架构。但MoE并不是最新发展的技术,早在90年代,便有相关思想的孕育,乘着大模型的东风又一次起飞,实乃老树换新芽。接下来,我们将深入探讨MoE的各个方面。
第一章、 MoE的前世今生
1.1 MoE的设计理念
MoE的核心思想源于"分而治之"的哲学:通过一个门控网络(Gating Network)和多个专家网络(Expert Network)协同工作,仅针对每个输入激活一部分最相关的专家,从而在保证模型总体参数规模的同时,控制实际计算开销。 基本公式如下:
其中,是门控网络,负责生成专家权重分布;是第i个专家网络的输出;是最终输出。
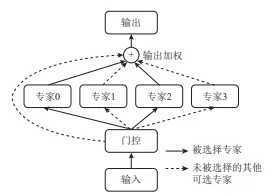
MoE与集成学习(Ensemble)的本质区别:
虽然MoE和集成学习都使用多个组件,但它们的核心机制截然不同。集成学习是让所有模型共同参与决策,典型如投票或平均,属于"集体决策"。而MoE则根据输入,通过门控网络动态选择一个或几个最相关的专家进行处理,属于专业分工。这种稀疏激活机制,使得MoE在参数量巨大的情况下,仍能保持较高的计算效率。
- 核心机制:稀疏 vs. 密集激活
- 标准MoE(稀疏激活):这是MoE的典型形式,通过门控网络(Gating Network)为每个输入动态选择少数专家(如1个或2个)进行激活。其他专家不参与计算,从而实现计算效率的提升。
- “密集型MoE”:如果所有专家都对每个输入进行推理,那么它在激活模式上确实与Ensemble相似(所有模型都参与)。但即使如此,MoE的输出通常是通过门控网络对专家输出进行加权求和,而Ensemble的输出可能是简单的平均、投票或堆叠(Stacking)。
- 训练方式:联合训练 vs. 独立训练
- MoE:专家网络和门控网络是联合训练的。门控网络学习如何根据输入分配权重,专家网络学习专精于不同的数据子集。训练过程中,门控和专家共同优化,形成一个协同系统。
- Ensemble:基学习器通常是独立训练的(例如,Bagging中的随机森林独立训练多棵树,Boosting中的模型顺序训练)。然后,在推理时组合它们的输出,没有动态的路由机制。
- 参数使用与计算效率
- MoE:即使所有专家都被激活,MoE的架构设计初衷也是为了提高参数规模而不线性增加计算成本。在“密集型”情况下,计算成本会很高,但这违背了MoE的典型优势(稀疏性)。
- Ensemble:计算成本与模型数量线性增长,因为没有稀疏激活机制,所有模型必须对每个输入进行完整推理。
- 设计目标
- MoE:主要目标是在保持高性能的同时,扩展模型参数规模(如达到万亿参数),并通过稀疏激活提高推理效率。它更注重模型容量和专业化分工。
- Ensemble:主要目标是提高预测准确性和鲁棒性,减少过拟合或方差,通过“集体智慧”来提升性能。
1.2 不同时代的MoE
DeepLearning时代前
MoE的思想最早可追溯至1991年Robert Jacobs和Geoffrey Hinton等人的开创性工作。他们提出通过一组"专家"子网络和一个"门控"网络,实现对输入数据的选择性处理,即仅激活与当前输入最相关的少数专家。这一时期的研究受限于数据和算力,未能引起广泛关注,但为后续发展奠定了重要理论基础。
DeepLearning时代
随着深度学习的兴起,尤其是神经网络的广泛应用,MoE研究迎来了新的活力。2010-2017年间,研究人员开始将MoE与深度学习模型结合,探索更复杂的专家结构和门控机制。这些工作主要集中在学术研究领域,试图解决模型容量与计算效率之间的平衡问题,为后续在大规模语言模型中的应用奠定了基础。
大模型时代
进入大模型时代,MoE从理论探索走向了产业应用的核心。2017-2020年,随着Transformer架构的提出和普及,研究人员开始尝试将MoE与Transformer结合。2020年至今,MoE已成为顶尖大语言模型的主流选择之一。
代表性模型包括:
- Switch-Transformer(Google):简化路由设计,提出单个专家激活
- GLaM(Google):在推理时使用显著更少的计算资源就超过了GPT-3的表现
- Mixtral 8x7B(Mistral AI):开源模型典范,总参数量庞大但激活参数量少
- DeepSeek系列:在细粒度专家和训练效率上进行了深度创新
大模型时代,MoE 的一个显著优势是它们能够在远少于 Dense 模型所需的计算资源下进行有效的预测。这意味着在相同的计算预算条件下,可以显著扩大模型或数据集的规模。特别是在预测阶段,与稠密模型相比,混合专家模型通常能够更快地达到相同的质量水平。例如 Google 的 Switch Transformer,模型大小是 T5-XXL 的 15 倍,在相同计算资源下,Switch Transformer 模型在达到固定困惑度 PPL 时,比 T5-XXL 模型快 4 倍。
国内的团队 DeepSeek 开源了国内首个 MoE 大模型 DeepSeekMoE。DeepSeekMoE 2B 可接近 7B Dense,仅用了 17.5% 计算量。DeepSeekMoE 16B 性能比肩 LLaMA2 7B 的同时,仅用了 40% 计算量。DeepSeekMoE 145B 优于 Google 的 MoE 大模型 GShard,而且仅用 28.5% 计算量即可匹配 67B Dense 模型的性能。
第二章、MoE的架构
接下来的介绍将基于大模型Transformer的范式
2.1 MoE总体架构
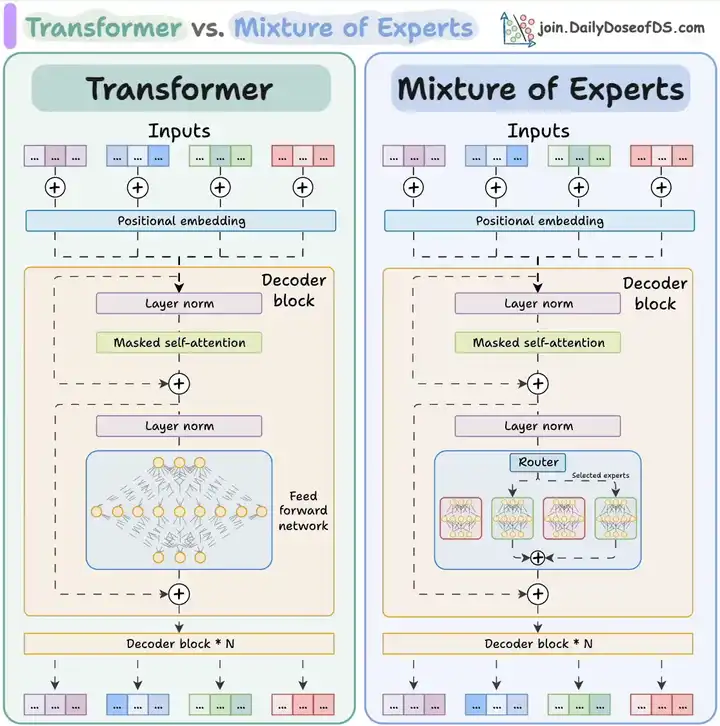
在LLM的Transformer中,MoE主要位于FFN层,原因是随着模型规模的扩大,FFN的计算量和参数量增加,例如,早参数量为540B的Palm模型中,这些参数的90%位于其FFN层内。
下图是Transformer添加MoE前后对比图,可以看出
MoE
MoE分为专家网络和路由(或称为门控网络)两大模块构成。
参照MoE的核心公式:
其中,是门控网络,负责生成专家权重分布,对应n个专家,每个专家本身是一个独立的神经网络,实际应用中,这些专家通常是前馈网络FFN,但也可以是更复杂的网络结构。实现了将传统Transformer中的FFN(前馈网络层)替换为多个稀疏(后面会解释)的专家层(Sparse MoE layers)
对应路由或称为门控网络,通常由MHA+LN的结果作为输入,通过一层线性层生成各个专家的权重分布,然后通过topk等方式选择前k个专家实现稀疏,决定输入的token发送给哪些专家,来加权计算得到最终结果,实现路由
2.2 专家网络
2.2.1 密集型MoE VS 稀疏型MoE
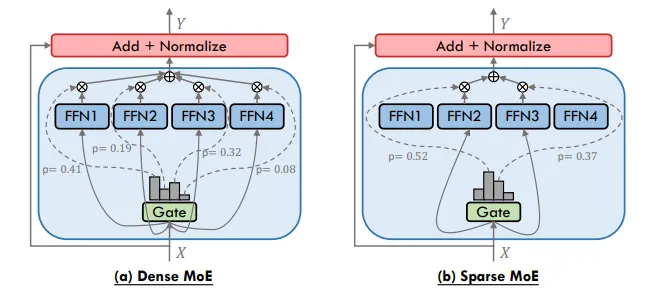
密集型MoE会激活所有专家网络,这一策略已被广泛应用于早起的一系列工作中,虽然可能会获得更高的准确性,但计算成本会很高,并不符合降低计算量的需求,因此当前大模型应用中主流通常是与之相对的稀疏型MoE;
稀疏型MoE只会激活路部分专家(由路由选择)
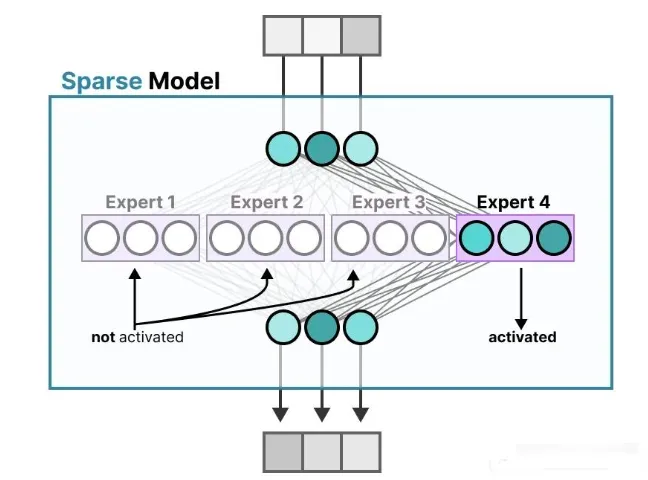
背后的思想是:每个专家在训练时学会了不同的知识。因此,在推理阶段也就是模型实际使用的时候 ,只会调用那些与当前任务最相关的专家。
当我们向模型提问时,系统就会选择最适合回答这个问题的专家:
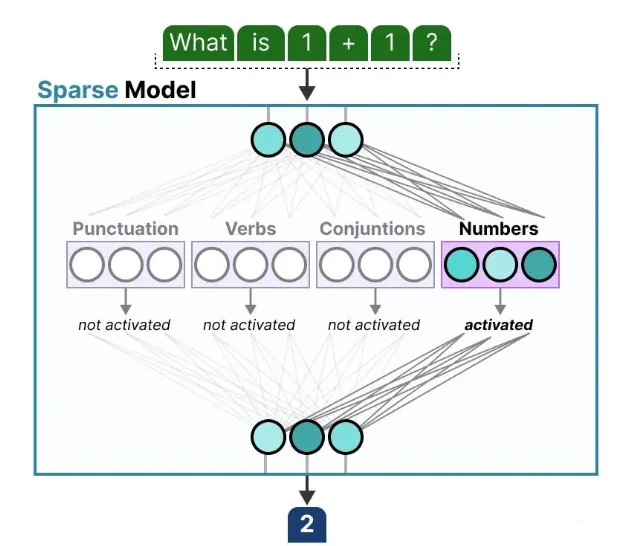
2.2.2 专家学到了什么
前边我们讲到了,专家所学的信息比起整个领域而言,是更为细粒度的信息。因此,有时称它们为“专家”其实有些误导人。
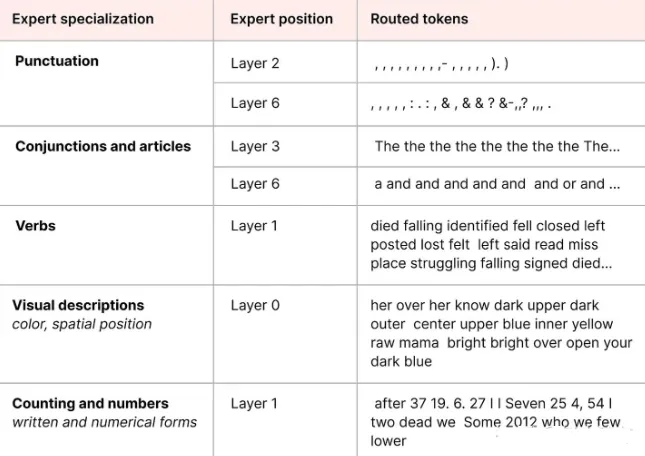
上图是 ST-MoE 论文中,编码器模型中专家表现出的专门化。大白话就是不同专家捕获的信息。
然而,解码器模型中的专家似乎并没有表现出同样类型的专门化。当然这也并不意味着所有专家都是一样的。
举个例子,在论文 Mixtral 8x7B 中,每个token都用第一个选择它的专家进行颜色标记。就是你一句话输入进去,不同的专家会注意到不同的token,每个专家用不同颜色表示,如果在这个句子中,某个词语第一次就被引导到某个专家,那就用这个专家的颜色进行标记。

这张图也显示,专家们更倾向于关注语法结构,而不是具体的领域知识。
因此,虽然解码器的专家看起来没有明显的专业领域,但它们好像会用于处理某些特定类型的token。
2.3 路由
现在我们已经有了一组专家,那模型是怎么知道该使用哪些专家的呢?
在专家模块之前,会加入一个路由器(router) (也称为门控网络 gate network),它是专门训练用于决定每个 token 应该交给哪一个专家来处理的。
路由器本身也是一个前馈神经网络(FFNN),它的作用是:根据每个 token 的输入内容,输出一组概率值,并据此选择最匹配的专家。
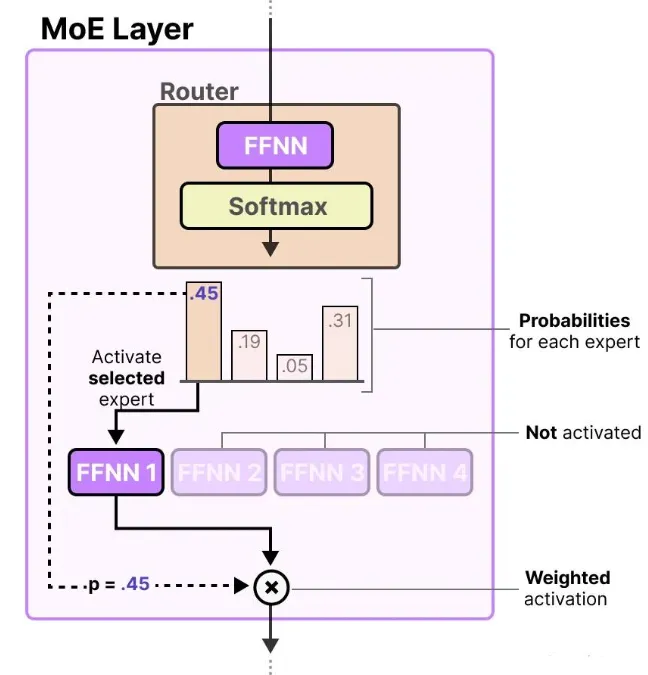
每个专家的输出会乘以对应的“门控值”(也就是刚才输出的概率),最终汇总后作为该层的输出。
路由器 + 一组专家(FFNN被选中的一小部分)= 构成了一个 MoE 层(MoE Layer) :
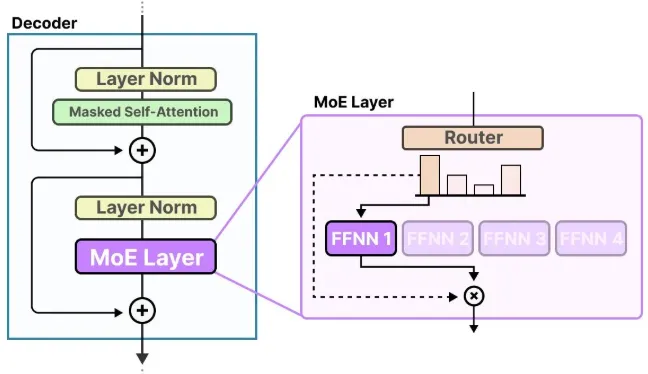
2.4 负载均衡
路由机制虽然简单,但实际上会出现一个问题,某些专家学得更快,导致路由器总是选它们。这样一来会导致一些问题 ,选择的专家不均匀,一些专家几乎不会被训练到,最终训练和推理时都容易出现偏倚和性能下降 的问题。
为了解决这个问题,引入了负载均衡(load balancing) 。它的目的是让每个专家在训练和推理中都能被公平地使用,避免某在某几个专家上过拟合。
2.4.1 KeepTopK策略
一种常见的路由负载均衡方法是通过一个叫做KeepTopK的简单的扩展,引入可训练的高斯噪声,以防止模型总是选中同一批专家:
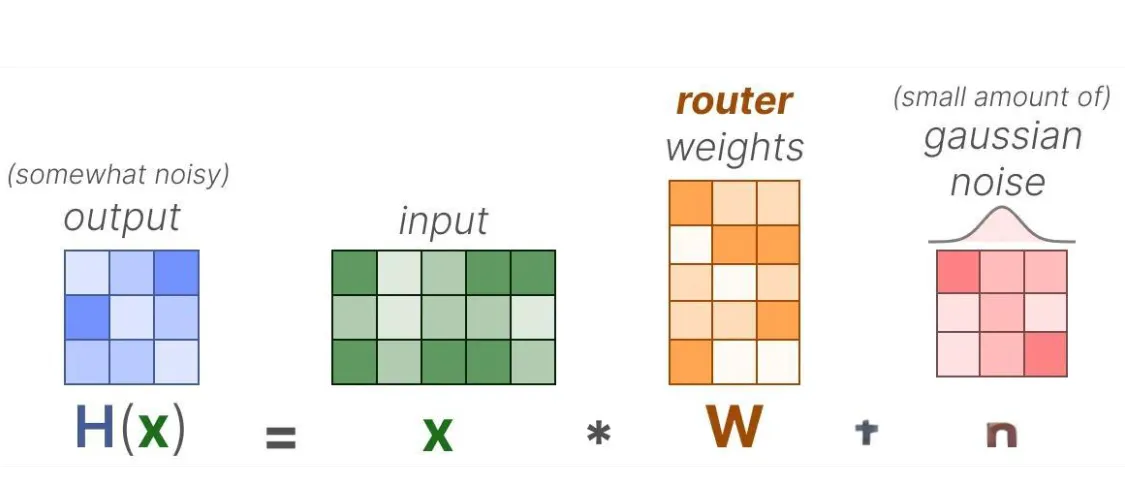
接下来,除了你想要激活的 Top-k 个专家(比如前 2 个),其他专家的分数全部设为 -∞:这样一来,在做 SoftMax 时,分数为 -∞ 的专家对应的概率就是 0,不会被选中 :
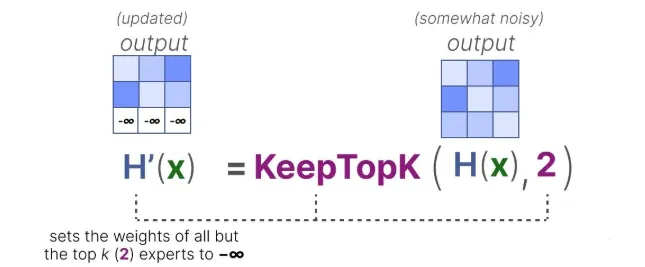
虽然现在也有很多好用的替代方案(新的 MoE 路由算法),但KeepTopK 仍然是许多大型语言模型中常用的策略。
而且,它可以加噪声,也可以不加噪声,都可以使用。
2.4.2 辅助损失
为了让训练过程中的专家使用更加平均,研究者在主损失之外,引入了一个辅助损失(Auxiliary Loss)(或者叫负载均衡损失(Load Balancing Loss))。
这个损失项的作用是强制每个专家在训练中有差不多的“重要性”。
辅助损失的第一步,是对整个 batch 中每个专家的路由概率值求和也就是统计在这个 batch 中,每个专家一共“被选中的概率”加起来是多少 :
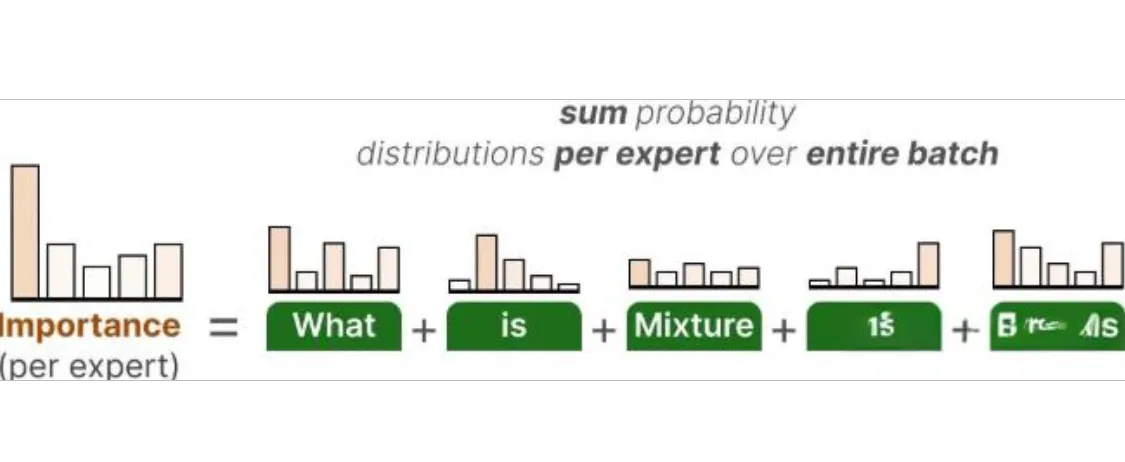
这样就得到了每个专家的一个重要性分数(importance score),表示这个专家在整个 batch 中,在不考虑输入内容的情况下,有多大可能被选中。
接下来,我们可以利用这些重要性分数,计算一个指标变异系数(Coefficient of Variation, CV) ,表示各个专家的重要性差异有多大:
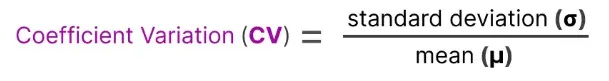
如果 CV 很高,说明某些专家总被选中,而其他专家几乎没被用;
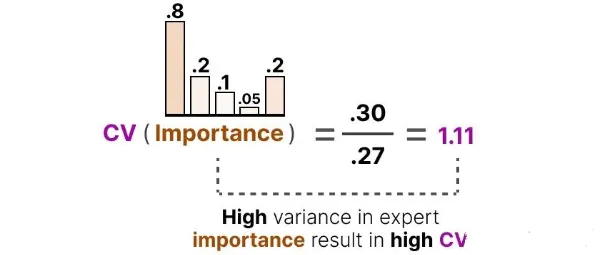
如果 CV 很低,说明所有专家被使用得差不多,这正是我们想要的“负载均衡”状态。
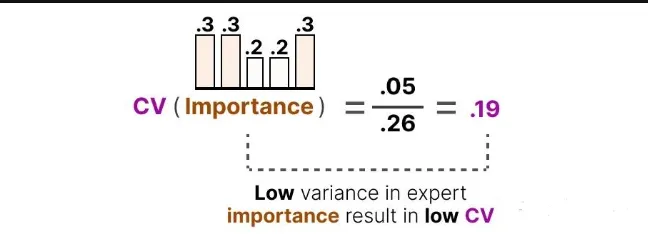
利用这个 CV 分数,我们可以在训练过程中不断更新辅助损失,使模型的优化目标之一就是尽可能降低 CV 值,从而让每个专家的使用重要性趋于一致:
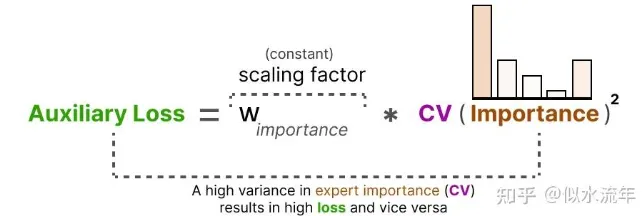
最后,这个辅助损失会作为一个单独的损失项,加入到整体训练目标中一起优化。
总结一下三步:
第一步:计算每个专家的“重要性分数
第二步:计算“变异系数
第三步:优化目标 = 降低 CV
第四章、MoE代码参考
可参考从零实现一个MOE(专家混合模型),写的很清楚
参考
A Survey on Mixture of Experts in Large Language Models
混合专家模型(Mixture of Experts,MoE)详解(附代码)
本文作者:brucewu
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!