目录
一. 概述
Google研发推荐和搜索领域的深度学习模型-DCN(Deep&Cross Network),前后共推出两个版本,在先前的文章:Deep & Cross Network (DCN), 已经介绍了DCN-V1,DCN虽然能自动的学习特征交叉,但在web级流量(理解为大规模样本)模型中,DCN有以下局限:
- 表达能力不足:交叉网络的多项式类仅由 O (输入规模) 个参数刻画,限制了对随机交叉模式的建模灵活性。
- 容量分配失衡:应用于大规模数据时,DNN 会占用绝大多数参数学习隐式交叉,导致交叉网络的能力未被充分利用。
为了提高其在大规模工业场景的实用性,DCN-V2相应而生。
DCN-V2相对于前一个版本,有以下几个主要改进点:
- Wide侧-Cross Network中用矩阵(可低秩分解)替代向量;
- 提出2种模型结构,传统的Wide&Deep并行 + Wide&Deep串行
- 使用MoE进一步增强特征提取能力
二、DCN-v2架构
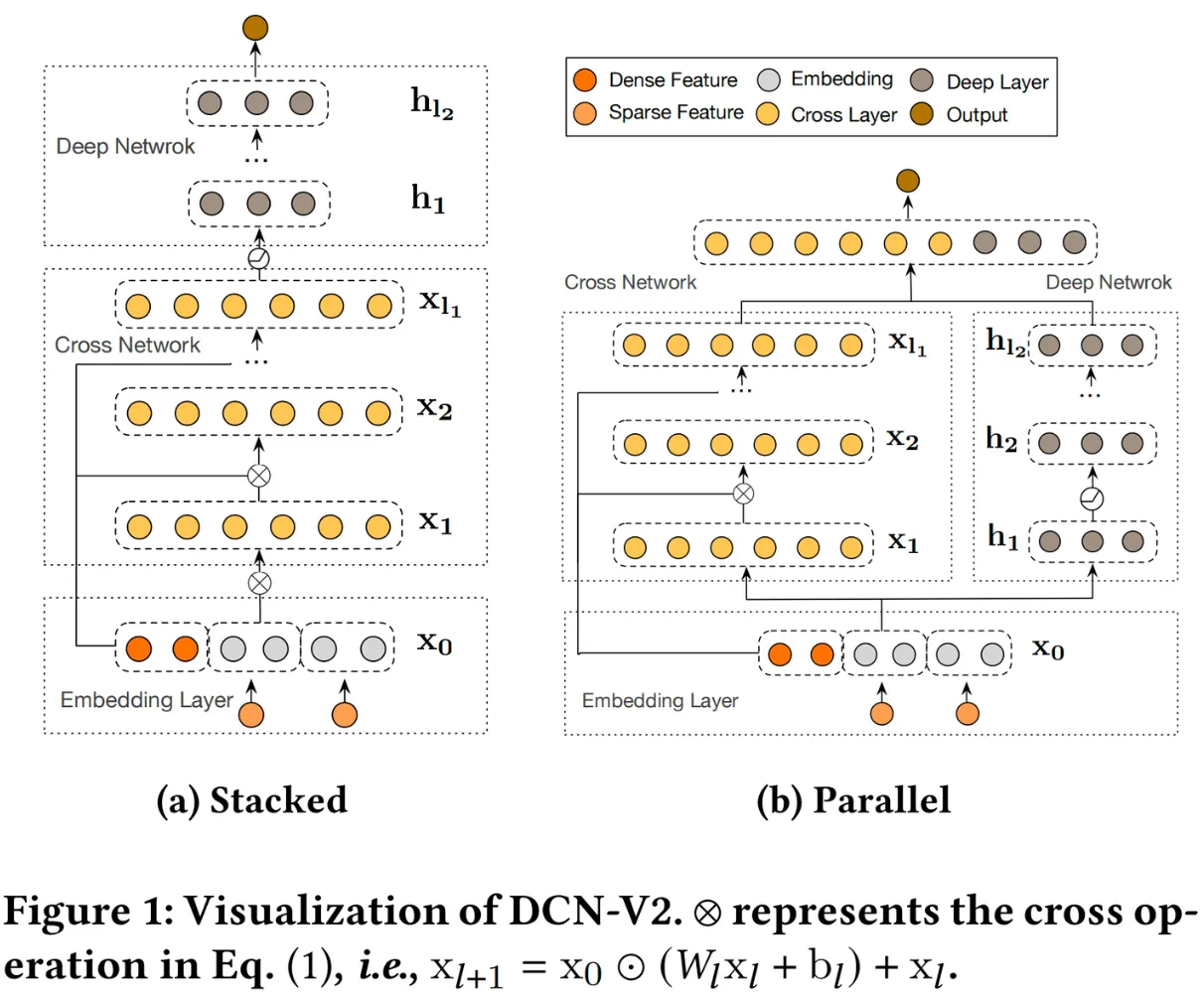 如图,DCN-v2可以分为串行结构(Stacked)和并行结构(Parallel),两者在不同的数据集上有着不同的表现,串行结构在criteo数据集表现更好,并行结构在Movielen-1M数据集上表现更好。
如图,DCN-v2可以分为串行结构(Stacked)和并行结构(Parallel),两者在不同的数据集上有着不同的表现,串行结构在criteo数据集表现更好,并行结构在Movielen-1M数据集上表现更好。
DCN-v2主要由三个部分组成:Embedding Layer、Deep Network和Cross Network。其中Embedding Layer和Deep Network可以参考先前的文章:
2.1 DCN-v2与DCN-v1在Cross Net的改进点
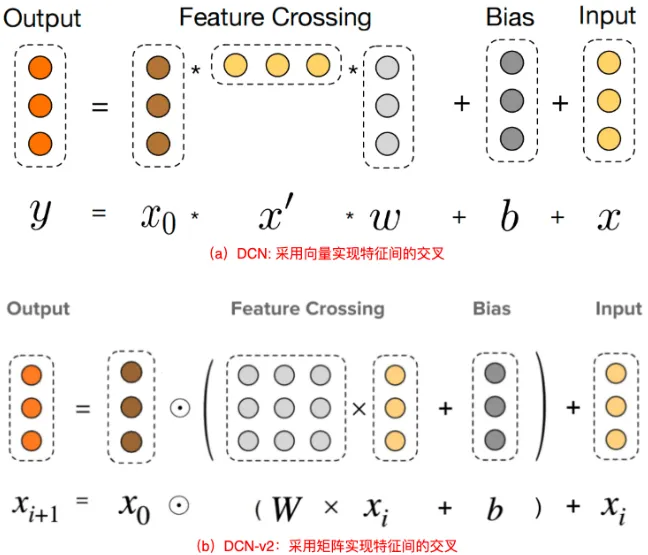
从图中可以看出,DCN-v1(或DCN)中的在进行特征交叉时,是使用向量 来进行的,所以DCN-v1通常也被称为DCN-Vector,简称DCN-V;DCN-v2是使用矩阵 来进行特征交叉的,所以它也通常被称为DCN-Martix,简称DCN-M,显然它的的参数量更大,能提高模型的表达能力,这也是上面提到的 DCN的表达能力在大规模数据中不足的原因。DCN-v2的Cross Net计算公式如下:
由于DCN-v2使用矩阵代替向量,在大规模工业场景中,会带来计算量和存储量的暴涨,当输入的 维度为 时,对应矩阵 的维度为 ,参数量为之前的 倍,在实际中很难接受该成本,研究者发现,对于训练出来的矩阵 ,它是低秩的。如下图所示,学习到的矩阵的奇异值衰减很迅速
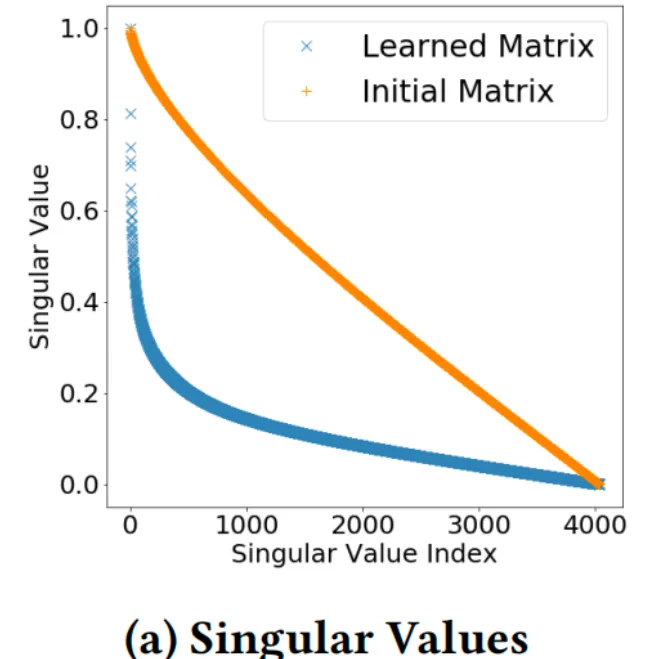
于是刚好可以做低秩分解:
矩阵的低秩分解可以见笔者先前的文章:
对于CrossNet每层训练的矩阵 , 分解成两个小矩阵相乘:
其中
每层的特征交叉公式变为:
此时, 和 的参数量相比原矩阵 就要少很多了。
2.2 使用MoE进一步增强特征提取能力
既然训练矩阵都可以分解为小矩阵了,那就完全可以使用MoE了,毕竟MoE其实就是进一步将并行的矩阵变得更多,最后加权求和。
MoE通常由两个部分组成:Expert(专家),通常由一个小网络组成;Gate(门控网络),通常由一个函数组成。DCN-v2利用多个专家分别在不同子空间中学习特征交叉,并使用依赖于输入 的门控机制自适应地组合学习到的交叉特性,具体可见下图:
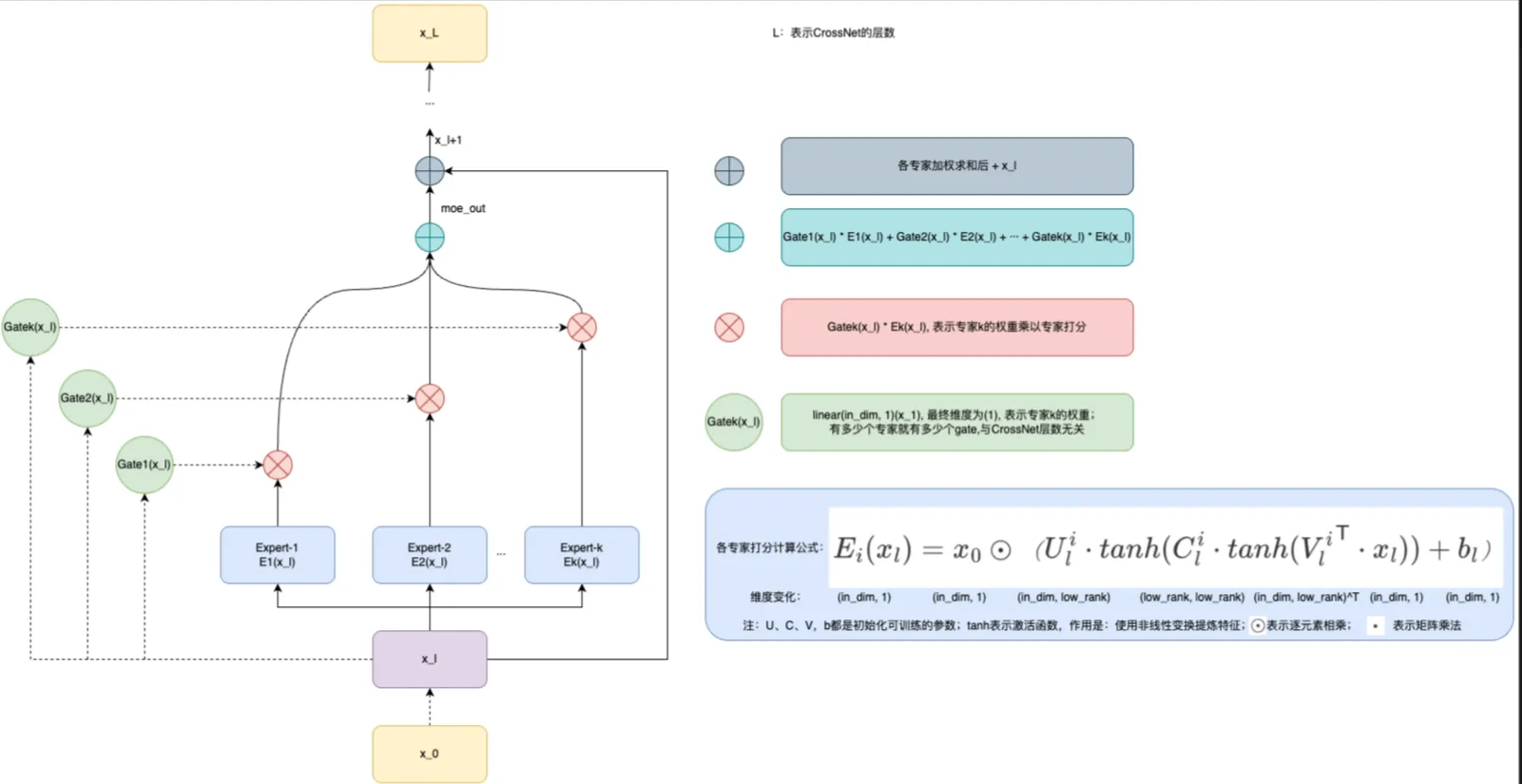
Exper(专家)部分:在每一层的特征交叉中,一共 个,每个专家都会经过一个小网络,即组成,其各自的维度可见上图的维度变化,在专家网络计算时,作者并没有立即从维度投影回(),而是进一步在投影空间中应用非线性变换来优化表示,非线性变换即为非线形激活函数,常使用函数,所以在计算之间都有一个 函数。
Gate(门控网络)部分:不用把门控网络想的非常高大上,实际就是用来生成每个专家的权重,常使用的 线形网络。
它们的公式化表现如下,每个专家网络的计算如下:
其中表示任何非线性激活函数。从到的计算如下:
本文作者:brucewu
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!