在当今大模型技术飞速发展的浪潮中,混合专家模型(Mixture-of-Experts, MoE)以其独特的稀疏激活特性,有效解决了模型规模与计算效率之间的平衡难题,已成为构建千亿乃至万亿参数大模型的核心架构。但MoE并不是最新发展的技术,早在90年代,便有相关思想的孕育,乘着大模型的东风又一次起飞,实乃老树换新芽。接下来,我们将深入探讨MoE的各个方面。
第一章、 MoE的前世今生
1.1 MoE的设计理念
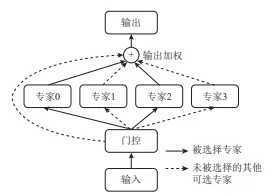
MoE的核心思想源于"分而治之"的哲学:通过一个门控网络(Gating Network)和多个专家网络(Expert Network)协同工作,仅针对每个输入激活一部分最相关的专家,从而在保证模型总体参数规模的同时,控制实际计算开销。 基本公式如下:
其中,是门控网络,负责生成专家权重分布;是第i个专家网络的输出;是最终输出。
一. 概述
Google研发推荐和搜索领域的深度学习模型-DCN(Deep&Cross Network),前后共推出两个版本,在先前的文章:Deep & Cross Network (DCN), 已经介绍了DCN-V1,DCN虽然能自动的学习特征交叉,但在web级流量(理解为大规模样本)模型中,DCN有以下局限:
- 表达能力不足:交叉网络的多项式类仅由 O (输入规模) 个参数刻画,限制了对随机交叉模式的建模灵活性。
- 容量分配失衡:应用于大规模数据时,DNN 会占用绝大多数参数学习隐式交叉,导致交叉网络的能力未被充分利用。
为了提高其在大规模工业场景的实用性,DCN-V2相应而生。
DCN-V2相对于前一个版本,有以下几个主要改进点:
- Wide侧-Cross Network中用矩阵(可低秩分解)替代向量;
- 提出2种模型结构,传统的Wide&Deep并行 + Wide&Deep串行
- 使用MoE进一步增强特征提取能力
